In this edition of JVL blog, we will look into Git Versioning basics.
As programming projects become inevitably complex and extensive, it is imperative and also logical to keep control of your source code while being able to work in a collaborative team. Sometimes even keeping track of changes in your own source files becomes a very difficult task as the project scales. Then imagine having to work with a team of 3 or more people! It becomes hardly manageable. Software Versioning tools such as SVN, Git, ClearCase, Mercurial exist to help alleviate this problem.
Of the mentioned examples, I have had experience with SVN and Git, which are both quite similar, and Clearcase, which is a very powerful source control tool more suitable for very large-scale projects. As I prefer Git, I will be writing about it.
An Introduction to Git
Git is an open-source source code versioning utility that is both powerful and quite easy to learn. Despite its intended use for software source codes, Git could be similarly used to version control any project that handles files such as VHDL (Very High-Speed Hardware Description Language) projects, circuit schematics, graphics designs, documentations, etc... It is sub-optimal to handle graphics with Git, because the information contained is not text-based. Nonetheless, taking snapshots of graphics is equally possible with Git. Many GUI programs exist for Git, but I will be focusing entirely on working with Git in the command lines (either under Linux or Windows).
The idea of versioning control of Git is creating snapshots of your source codes during the span of the project and storing those snapshots into repositories, which could be locally saved or hosted by providers like Github, BitBucket, and Gitlab. The snapshots contain the state of the different files at the moment the snapshot was taken. In other words, it saves the changes of the files up to the point the snapshot was taken. Of course, the user can specify which files to keep track of by Git. These snapshots, or in Git's lexicon commits, could be later examined, retrieved, reused, deleted....
Getting Started
The basic, general workflow is shown as follows:
 |
| Figure 1. Git Versioning Basic Workflow |
1. Starting a Repository
The way I prefer to do it is to first log in into my repository-hosting provider (BitBucket) and create a repository from there, as shown below:
 |
| Figure 2. Creating Repository in Bitbucket |
Then copy the address of the repository to the clipboard.
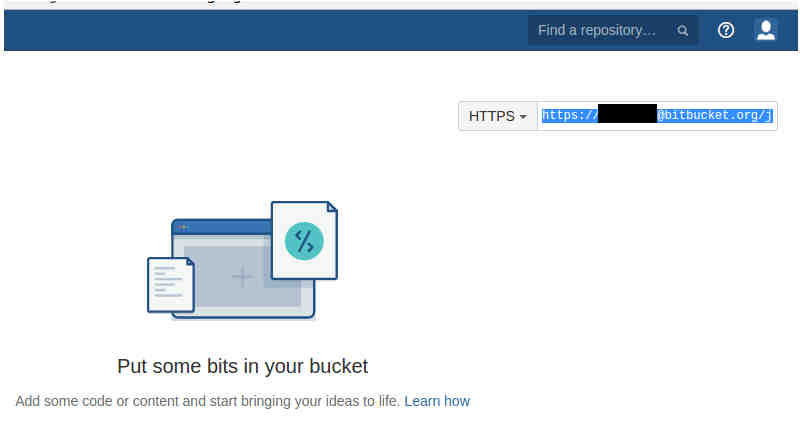 |
| Figure 3. Copying the Repository Address to your Clipboard |
Open a terminal, navigate to your desired location, and clone the repository locally with the "git clone" command.
 |
| Figure 4. Cloning the Repository from the Hosting Provider |
2. Making Changes
 |
| Figure 5. Copying two Files into the Project Folder. |
Bonus: use "git status" to view the current repository changes. I use this a lot; sometimes I think way too often.
 |
| Figure 6. Viewing the Status of the Repository |
2. Staging Changes
Staging changes simply tells the program which files or changes to actually take a snapshot of. We do this by using "git add ." to stage all files to be committed. Instead of using "." to stage all files, one could specify individual files.
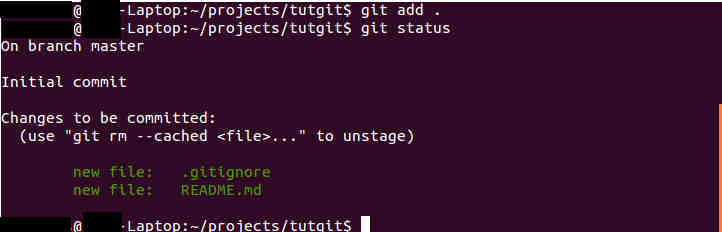 |
| Figure 7. Staging Changes |
Committing is the same as taking a snapshot of current staged files. This is done with "git commit" command.
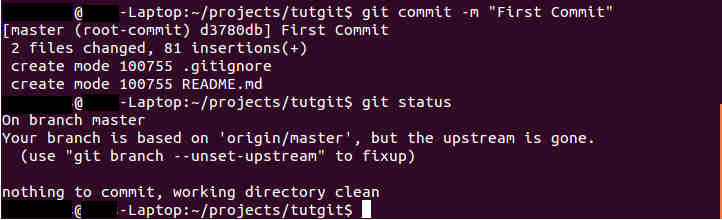 |
| Figure 8. Committing Staged Changes |
The "-m" option specifies a message between "" describing briefly the current snapshot, so to speak.
Bonus: use "git log" to view a history of your commits, or snapshots. The most recent commit is now visible in the log.
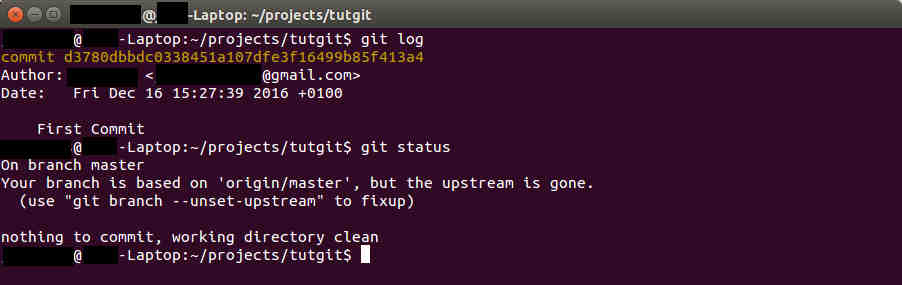 |
| Figure 9. Viewing Commit History |
Lastly, we have to "git push" so that the local changes are updated on the server.
 |
| Figure 10. Pushing Changes to the Server |
If you encounter a message as shown in Figure 10 after issuing the "git push" command, then follow as it has been done in the same screenshot. Afterwards, you should be able to successfully push the changes. You might also be asked for credentials of your account with the repository hosting provider.
At this point, the steps just repeat in a cycle as was shown in Figure 1. This workflow can get you started just as essentials. Obviously, there are tons of other actions and features of Git that are not exposed here. From here on, you could seek some more advanced topics and features from Git. Google is your best friend, and the sky is the limit...
Conclusion
I hope this was as instructive as I had anticipated it to be and also hope that Git will make your life much easier and productive!
